Schema Overhaul
Background
The GO database is currently crucial part of the GO infrastructure.
- Underpins AmiGO
- Underpins PAINT
- Used by annotation group in QC checks
- Used by users in GOOSE queries
- Mirrored in a number of different places for in-house use
However, the GO db was designed in 1999 and the core remains largely unchanged. In addition, the existing perl architecture is highly inefficient and depends on the outdated go-perl library.
New requirements:
- incremental loading rather than rebuilding
- fast text search
- efficient queries
- use of relation chains (implemented in QuickGO)
- relation filtering
- use of other ontologies for col16 queries and term enrichment
- better visualization
- Increasing_Expressivity_in_GO_Annotations open ended (cf LEGO, col16)
- open ended increased ontology expressivity (OWL, "cross-products")
- increased integration between ontology and annotation workflows
- annotation QC, Rule Engine support
Overview of plan
We will overhaul the GO database schema and in parallel explore other storage/index options. For example, we will use SOLR for all text-oriented search. In fact, SOLR can fulfil a number of query capabilities. See Full_Text_Indexing.
The efficiency considerations may change depending on AmiGO_and_QuickGO_Integration. QuickGO is not backed by a relational database, it uses a custom index engine. This, together with the increaed use of SOLR will make the focus of the RDB more towards advanced queries and internal QC purposes.
Schema Overhaul
We will explore a more efficient relational structure. This may involve abandoning integer surrogate keys, which hamper incremental loads.
This new schema is currently called GOLD (Gene Ontology Latest Database). The current/old mysql one is called LEAD.
We will focus immediately on developing tools for GOLD. We will have a means of populating a Lead instance from a Gold instance. We can start switching to this schema early on, and support both schemas in parallel.
The overall strategy will be to focus on new java middleware. This middleware can update and access both the existing schema and a redesigned schema. This way we gain immediate short term benefit at the same time laying a sustainable path for the future.
Architecture
{kind=link}
Dataflow
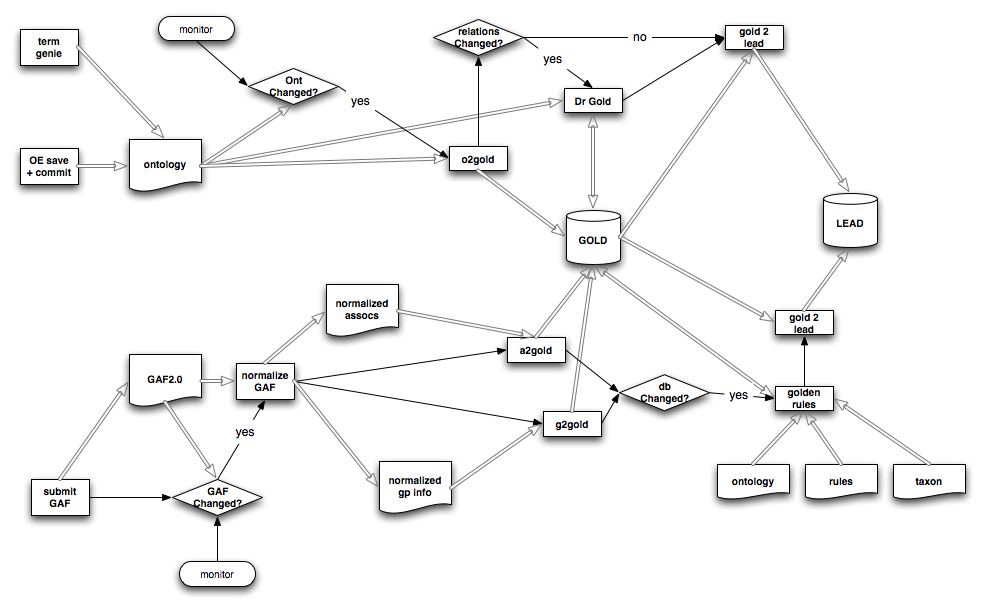{kind=link}
Deliverables
The majority of these will be delivered by the 2+ ARRA developers.
OBO Access Layer
A java ontology API layered on the OWLAPI. This will implement the Repository enterprise pattern and will form a simple thin layer for simplifying access to the OWLAPI according to the OBO Format 1.4 specification. For example, methods such as:
String getTextDefinitionForClass(OWLClass cls); Map<String,OWLClass> getSynonymMapForEntity(OWLEntity e);
The developer will work with CM on the specification, and the developer will provide the implementation. This layer will differ from the existing OboEdit OBO API in that it does not have its own object model - rather it uses the OWLAPI object model and provides GO/OBO-friendly methods for accessing and manipulating OWL. Note that in future obof will be considered an OWL syntax and will be accessed via the OWL API.
Time: 1 month
Java Ontology Loader
Create a bridge between the OBO access layer and GHOUL (GO Hibernate layer). This will allow the loading and updating of the ontology portion of the GO database from OBO files via the OWLAPI.
Note that GHOUL will continue to be used for the existing db schema.
Time: 1 month
GAF Parsing and Object Model
Write or reuse java GAF parser and object model.
Object model representation must mirror normalized association file /
gp info file structure, include col16 and col17.
Time: 1 month
GOLD db Loader
The dataflow has two parts:
- split GAF2.0 into normalized assoc file and gp_info file (Amelia to specify)
- normalized files loaded into db
Time: 1 month
LOEAD db Loader
Load LEAD (old schema) from GOLD (new).
Time: 1 month
Extend/Replace OWL API OBO Parser
The current OWLAPI OBOParser has some flaws.
Extend or replace the OWLAPI OBOParser as required. In particular, extend existing support for synonyms, text definitions etc, implemented according to obo format 1.4 spec, using IAO and purl.obofoundry.org URIs.
Time: 1 month and ongoing
Switch to load-qfo-seqs.pl
Retire load-seqs-into-db.pl
Time: 1 week
Java Seq Loader
Time: 1 week
Create tree loader
Takes nhx file (from Panther) as input. loads tree into db. written in java. coordinate object model with PAINT.
Db structures already exist. Tree should be stored both as text nhx blob and as normalized recursive structure.
Time: 1 week
Migrate SQL Reasoner to Java
See Transitive Closure for more background.
Migrate the existing GO perl/SQL rule-based reasoner to java, or replace with existing OWL reasoner that is guaranteed to complete within a given period of time. The existing reasoner is a simple forward-chaining implementation with simple hardcoded rules (subclass, transitivity, property chains). Currently it is extremely slow which will hamper incremental loading.
Classification using equivalence axioms is done ahead of time prior to database loading, so this is not required for the database infrastructure. The reasoner need only calculate the transitive closure using the correct semantics for relation transitivity and property chains.
In principle an OWL-RL reasoner should be able run as fast or faster than the existing implementation -- although there are subtleties; for example, the GO database must store all entailed <X SubClassOf some R Y> triples to be able to support existing queries, it's not trivial to calculate this using existing reasoner APIs.
Time: 1-2 months
Admin Servlet
Create a simple servlet interface to the database that will allow GOC members and production administrators to check on the progress of database loads and perform administrative tasks. This will be implemented using RESTlet, and will also allow programmatic access, returning JSON objects.
Time: 1 month and ongoing
Extend GHOUL
Extend GHOUL as required. This includes adding new convenience methods, benchmarking and optimizing based on the results of benchmarks. In particular extend GHOUL to support new phylogenetic protein family tree model in database.
Time: 1 month and ongoing
PAINT integration, phase 1
This will mostly come for free as PAINT uses GHOUL. However, PAINT should gradually move away from using GHOUL directly to using a standard java layer.
Time: 1 month and ongoing
Research Alternative Query/Storage options =
Investigate alternative storage/query options. These should be geared towards future requirements and increased expressivity. E.g. OWL Databases, RDF triplestores.
Time: (optional at end) 1 month.
Deployment
Create a VM of all software used in database building. Deploy on production, plus Amazon etc.
Time: 1 month, ongoing
Rule Engine
Implement rule system for providing live quality control of ontology and annotations. Spec provided by CM. For ontology QC much of this can be done using standard reasoners. Some annotation QC may require some kind of rule evaluation in a closed-world environment, possibly translated to SQL.
Time: 1 month
Schema Redesign (S2)
The existing schema is inefficient for querying and loading.
The schema redesign project will be ongoing in the background for the first 6 months in an experimental/exploratory phase, followed by concretization as the graint aims become crystalized. Key questions to be addressed include the status of advanced nested post-composition (cf LEGO), evidence chains, integration with other data types.
Requirements that are certain include incremental loading and time travel. A common request is to compare annotations from two timepoints.
To satisfy requirements it is likely the schema will not employ integer surrogate keys, instead using public identifiers (a surrogate key layer can be automatically created if need be).
Time: background and then 2 months
Integrate S2 and java layer
May be via Hibernate and/or bulkloads.
Time: 2 months